
مع نمو النماذج اللغوية واستحقاق نعتها بالضخمة تعسَّر تشغيلها على الأجهزة العادية، وصار لازمًا على من أراد سبر أغوارها استئجار أجهزة محترمة فيها “رامات” أكثر ومعالجات أقوى. والعلاقة بين حجم النموذج اللغوي والحاجة إلى موارد محترمة علاقة طردية؛ فحجم النموذج كما نعلم يُقاس بعدد المعاملات التي دربها (Weights)، والمعامل رقم عشري يخزن بوحدة البت، فمثلًا النسخة الأكبر من نموذج (GPT-3) تحوي 175 بليون معامل، وكل معامل طوله 16 بت، إذا أردت استخدام هذه النسخة من النموذج ستحتاج إلى ذاكرة قدرها 350 قيقا بايت!
لنفترض أنك تريد موائمة نموذج (GPT-3) على بيانات عملائك، ستحتاج إلى أضعاف حجم النموذج لتخزين معاملات التدريب الأخرى (قيم دوال التنشيط والتحسين..) أي إلى كم هائل من الذواكر العشوائية فقط لتعالج هذا القدر من المعاملات.
- المعاملات الأوزان (Weights):
- معاملات وأوزان الشبكات العصبية، وهي أعداد عشرية تتغير قيمها خلال عملية التدريب، وتهدف عملية تدريب النموذج إلى إيجاد أفضل قيم لها. المعاملات مصطلح أشمل من الأوزان لكن في هذه المقالة نستخدمهم للإشارة إلى شيء واحد.
- موائمة (Fine-Tuning):
- الاستفادة من نموذج تم تدريبه مسبقًا في مهمة جديدة.
الحقيقة لا أستطيع تخيل أحد يحاول موائمة (GPT-3)، أولًا لأن (OpenAI) قررت من وقت إطلاقه أن تتحول إلى (ClosedAI) ولم تتح أوزانه للعموم أصلا، وثانيًا الاستفادة من نموذج بهذا الحجم قد لا تتطلب موائمة من الأساس، وقد لا تحتاج إلى نموذج بهذا الحجم لحل المشكلة أصلا؛ لكن ضربنا المثال مع نموذج (GPT-3) لتوضيح حجم المشكلة، وضرورة وجود حل لها.
تٌعرف الموائمة بأنك تأخذ نموذج متدرب من (Huggingface) مثلًا، وتكمل تدريبه على بياناتك الخاصة. هذه طريقة، وثمة طرق أخرى تجعل الموائمة أكثر كفاءة، وسنعطي نبذة عن أربعة طرق مشهورة في هذا المقال، وهي:
- نقل الخبرة (Transfer Learning)
- هندسة الأوامر (Prompt Engineering)
- التكميم (Quantization)
- لورا، كلورا
الطريقة الأولى: موائمة النموذج باستخدام "نقل الخبرة"
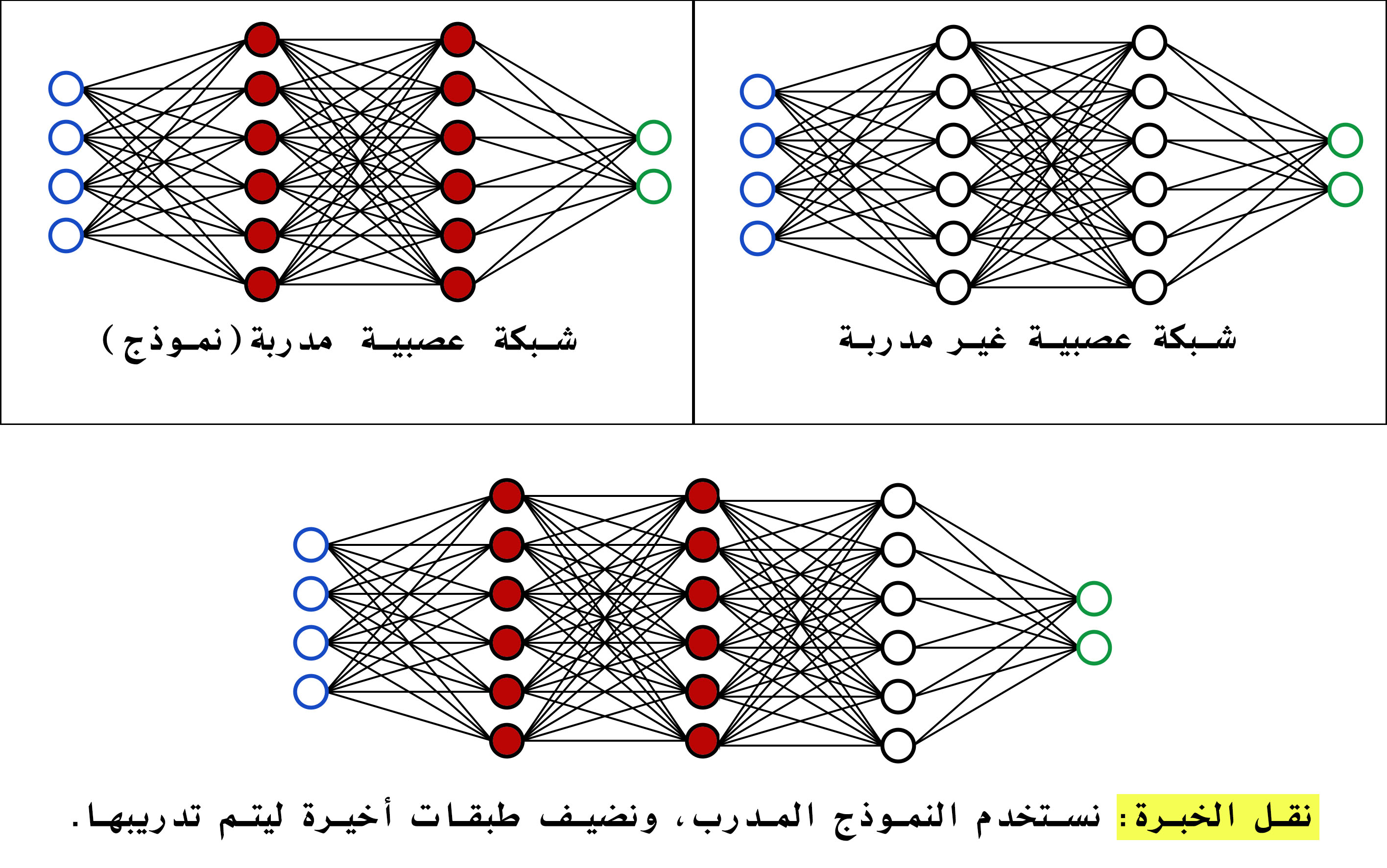
فيه نماذج كثيرة متاحة للعموم، مثلا دُرب نموذج (ResNet50) على بيانات (imageNet) وأُتيح للاستخدام في مكتبة (Keras). لنفترض أنه طٌلب مني عمل نموذج لتصنيف صور أشعة الرئة إلى رئة سليمة أو رئة مريضة. ممكن أدرب معمارية (ResNet50) على بياناتي من البداية، وممكن أستفيد من خبرة النموذج الذي تم تدريبه وإتاحته على مكتبة (Keras)، إما باستخدام النموذج وأوزانه الحالية كنقطة بداية لتدريب كامل معمارية (ResNet50) على البيانات التي عندي، أو بتثبيت أوزان النموذج التي انتهت من التدريب، والتعديل على معمارية النموذج بإضافة طبقات آخرها، وتدريب أوزان الطبقات الأخيرة فقط. هذه طريقة نقل الخبرة نستفيد من الأوزان المنشورة كما هي دون تدريبها.
أولًا: تتُرك الطبقات الأولى للنموذج ثابتة دون أي تغيير على الأوزان المنشورة
ثانيًا: تُضاف طبقات جديدة نهاية النموذج مخصصة للمهمة الجديدة أو البيانات الجديدة كما هو موضح في الصورة بالأسفل
يتم تدريب الطبقات الجديدة فقط، ويُستفاد من الطبقات الأولى في تسريع التدريب وزيادة الأداء. والنتائج التي تحققها هذه الطريقة مبهرة إذا أحسنت اختيار النموذج الذي ستستخدم أوزانه.
الطريقة الثانية: موائمة النموذج باستخدام هندسة الأوامر
نستخدم (الأوامر) في تعاملنا مع تطبيقات النماذج اللغوية الضخمة مثل (ChatGPT) و”جيمني”، ويمكننا استخدام هذه الأوامر مباشرة بدلًا من موائمة النموذج كاملًا لمهمة جديدة. لنفترض أن عندنا مشكلة تصنيف تجارب العملاء إلى (راض، محايد، غير راض)، باستخدام (أمر) مثل: “صنف النص التالي إلى (راض، محايد، غير راض)”، سنتمكن من الاستفادة من مزايا النموذج اللغوي والحصول على نتائج جيدة دون الحاجة إلى موائمته من الأساس.
لاحظ أن الأمر السابق ألفته بنفسي، ولأحصل على نتيجة أفضل يمكنني تجربة عدة صيغ لنفس الأمر، ثم أقارن نتائجها، حتى أجد الصياغة الأفضل، ويسمى هذا الأسلوب (موائمة الأوامر يدويًا).
لكن أين الموائمة في الموضوع؟
الطريقة السابقة لا تبدو كموائمة، فأوزان النموذج لا تتغير؛ لذا ثمة أسلوب آخر اسمه (موائمة الأوامر المرنة) يهدف إلى جعل النموذج يجد أفضل أمر بنفسه.
كيف؟ يتم تضمين الأمر بعد تجزئته ورقمنته إلى المدخلات، ثم تتم الموائمة على الأمر فقط، دون أي تغيير في الأوزان، وتسمى هذه الطريقة بالإنجليزية (Prefix Tuning).
يمكنك تجربة هذه الطريقة باستخدام مكتبة (PEFT) من (Huggingface)
https://huggingface.co/docs/peft/main/en/task_guides/clm-prompt-tuning
- تدريب نموذج (Model Training)
- تغيير قيم الأوزان حتى تصل إلى أفضل قيمة لها، وأفضل قيمة هي التي يصل معدل خطأ النموذج معها إلى أدنى حد
الطريقة الثالثة: التكميم (Quantization).
حتى الآن كل الطرق السابقة تحل المشكلة بتقليل عدد الأوزان التي تتغير. لكن طريقة التكميم تقدم حلًا تتغير فيه قيم الأوزان مهما بلغ عددها بكفاءة! طريقة التكميم لا تستبعد أي وزن، ولا أي طبقة، لكنها تنفذ على الأوزان عملية تكميم، تشبه عملية تكميم المعدة، لكننا هنا نتحدث عن تكميم الأوزان، أي تقليص حجمها. مصطلح التكميم عمومًا يعبر عن جعل الشيء في كمية محددة، ويعني في سياق تعلم الآلة باختصار تصغير حجم المعاملات، فبدلًا من أن يكون حجم المعامل الواحد 32 بت، نقلله إلى النصف أو الربع، وبالتالي يقل حجم النموذج نفسه إلى النصف أو الربع!
لنوضح الأمر أكثر في سياقه، ذكرنا في مقدمة المقال أن أوزان الشبكات العصبية عبارة عن أعداد عشرية تمثل في النظام الثنائي بسلسلة أرقام طولها عادة 32 بت، إذ أنه يمكن تمثيل العدد العشري بدقة عالية باستخدام هذا الطول.
لكن ماذا لو تم تقريب العدد العشري؟
لنتخيل النتيجة فقط، ماذا لو قربنا العدد 23.233453 إلى أقرب جزء من ألف، أي إلى: 23.234؟ سيصبح العدد العشري أقصرًا فقد أزلنا 3 خانات؛ ولأننا أزلنا 3 خانات قلت دقة تمثيل العدد. لا شك أنه بتقليلنا دقة تمثيل الأعداد سيقل أداء النموذج، لكننا سنوفر قدرًا كبيرًا من الذاكرة، وسيكون التعامل مع النموذج أسرع. هذا ما تفعله عملية التكميم، فهي تقلص طول المعامل من 32 بت إلى 16 بت أو ربما أقل. وهذا التقليص يصغر حجم النموذج مما يمكِّن موائمته على بيانات جديدة باستخدام موارد أقل مما لو كانت المعاملات مخزنة بطولها الكامل. وحتى النموذج نفسه سيعمل على أجهزة ذات موارد أقل كالجوالات والساعات. وتتم عملية التكميم من خلال تطبيق معادلة تشبه معادلة التقريب (scaling) على معاملات النموذج، أو بالاستفادة من مكتبة (Bitstandbytes)
في الرابط التالي تطبيق عملي للتكميم: https://dbrpl.medium.com/quantization-using-bitsandbytes-f8bbeb6b4576
الطريقة الرابعة: لورا، كلورا
ألم تحل طريقة التكميم المشكلة؟ ألم تمكنا من تغيير جميع الأوزان أثناء عملية الموائمة؟! نعم هذا صحيح، لكن في المقابل قل حجم النموذج وقلت دقته كذلك، وبودنا لو وُجدت طريقة تمكننا من تغيير جميع الأوزان دون أن تقل دقة النموذج.لورا تقترح طريقة أكثر كفاءة للتعامل مع الأوزان، ولنكن دقيقين أكثر، طريقة أكثر كفاءة في تمثيل الأوزان. منذ بداية المقال ونحن نشير إلى الأوزان ونسميها أحيانًا المعاملات، وفي المثال الذي طرحناه في طريقة التكميم جعلنا الوزن يبدو كرقم عشري وحيد، لكن الحقيقة أن المعاملات في الشبكات العصبية مصفوفات، والعمليات التي كنا نقول إنها تصبح أسرع بعد التكميم هي عمليات ضرب المصفوفات ببعضها. وبالتالي يمكن الاستفادة من خصائص المصفوفات في تطوير طريقة تسهل التعامل معها في الشبكات العصبية، وهذه هي لورا.
لورا اختصار للموائمة بتقليل رتبة المصفوفة (LOw-Rank-Adaption)، وهنا نتوقف قليلًا لفهم رتبة المصفوفة (Matrix Rank).
تعرف رتبة المصفوفة رياضيًا بأنها عدد الصفوف (أو الأعمدة) المستقلة خطيًا. أحيانًا يكون بين صفوف المصفوفة (أو أعمدتها) علاقة خطية ما، كأن يكون الصف الثاني ضعف قيم الصف الأول، وفي حال وجود علاقة أو اعتماد في الصف على غيره لا يعتبر مستقلًا، وبالتالي يستبعد أثناء حساب رتبة المصفوفة.
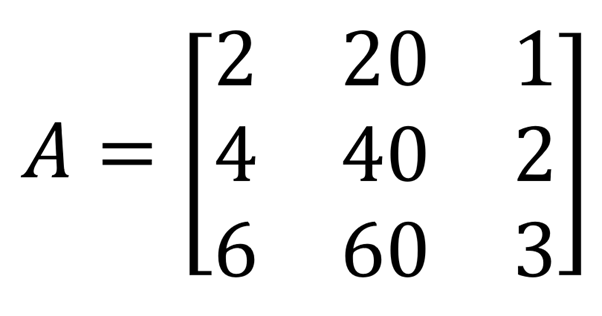
لنمثل بالمصفوفة السابقة (A) وحجمها (3×3). عند حسابنا لرتبتها بأحد طرق حساب الرتبة سنجد أنها من الرتبة الأولى؛ والسبب هو أن الصف الثاني معتمد على الصف الأول، إذ يمكننا إيجاد قيمه بضرب الصف الأول في 2. والصف الثالث كذلك معتمد على الصف الأول، إذ يمكننا إيجاد قيمه بضرب قيم الصف الأول في 3. إذًا فالصف الوحيد المستقل هو الصف الأول، فلذا رتبة المصفوفة هي واحد.
بمعرفتنا رتبة المصفوفة (A) يمكننا إعادة كتابتها لتصبح حاصل ضرب مصفوفتين أقل حجمًا، وبتقليل حجم المصفوفة تقل عدد المعاملات التي يتم تحديثها رغم أن القيمة الفعلية للمعاملات لم تتغير. والصورة التالية توضح كيف تمت إعادة كتابة المصفوفة (A) بأنها نتيجة (B×C)
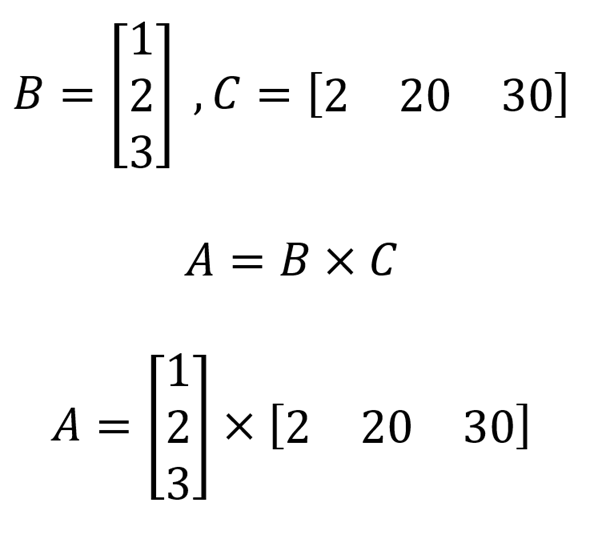
في لورا، يتم تجزئة مصفوفة (W∆) إلى مصفوفتين كما جزئت المصفوفة A في المثال إلى مصفوفتين (B×C) وتتم العمليات على (B×C) الأبسط تمثيلًا والأقل حجمًا.
أما كلورا، فزيادة على تمثيل مصفوفة (W∆) تمثيلًا أبسط وأقل حجمًا، يتم تطبيق التكميم كذلك على المصفوفات المجزئة (B×C)، وبالتالي تزيد الكفاءة، لكن لا تنسَ أن التكميم يقلل الأداء لأنه يقلل دقة تمثيل الأعداد.
أخيرًا.. الحمدلله، يعلم الله كم جلست هذه التدوينة في المسودات حتى كادت تتحلل، لكن تيسرت في النهاية وانتهينا منها بطريقة ما 😊 لا تزال طرق الموائمة تتطور أكثر فأكثر، جرب أن تبحث في قوقل سكولار عن (efficient fine-tuning) وانبهر بجدة النتائج. أخيرًا أنا أتعلم وتسعدني تعليقاتكم ونصائحكم على المحتوى الذي أشاركه، ودمتم في ود
- مصادر مفيدة
-
- https://www.youtube.com/watch?v=X4VvO3G6_vw
- https://byjus.com/jee/rank-of-a-matrix-and-special-matrices/
- https://arxiv.org/pdf/2106.09685
- https://ericwiener.github.io/ai-notes/AI-Notes/Large-Language-Models/Prompt-Tuning-and-Prefix-Tuning
- https://huggingface.co/docs/peft/main/en/task_guides/clm-prompt-tuning
- https://huggingface.co/docs/optimum/concept_guides/quantization